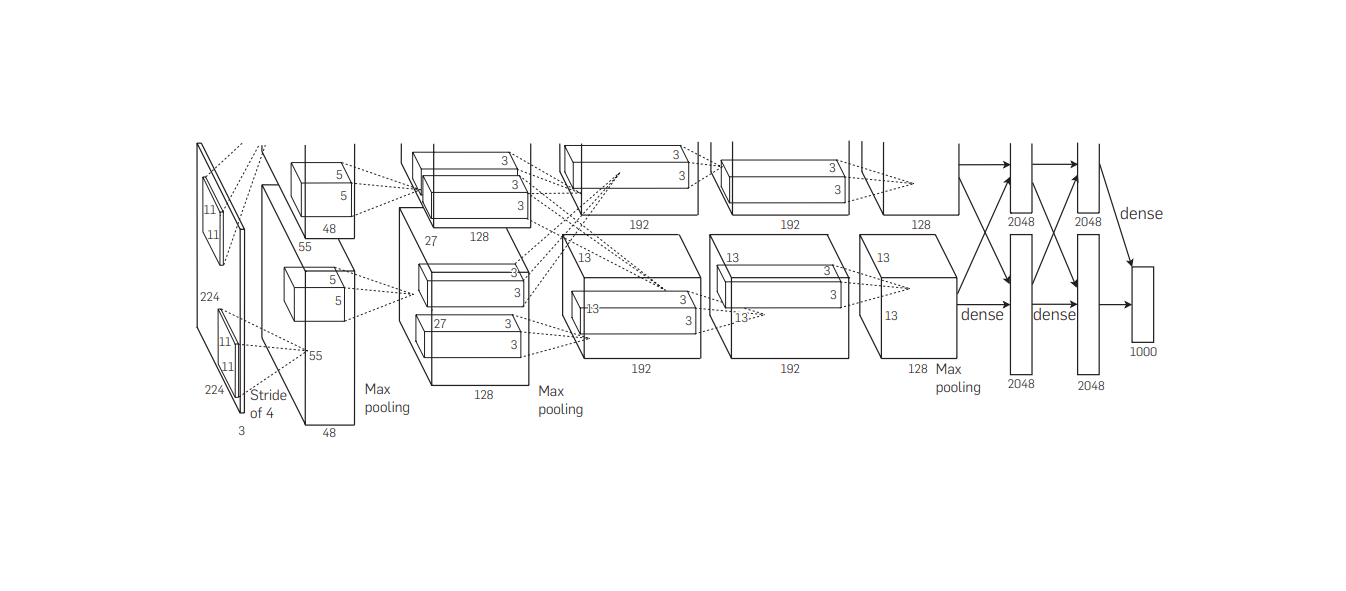



1.AlexNet理论
AlexNet模型与LeNet模型有很多相似之处,它可以被看作是LeNet的改进版本,都由卷积层和全连接层构成。然而,AlexNet之所以能够在ImageNet比赛中大获成功,还要归功于其独特的模型设计特点,主要包括以下几点:
(1)使用了非线性激活函数(ReLU)。
(2)丢弃法(Dropout)。
(3)数据增强(Data augmentation)。
(4)多GPU实现,LRN归一化层的使用。
论文名称:ImageNet classification with deep convolutional neural networks
下载地址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
视频讲解:https://www.aideeplearning.cn/mcv_lesson/772/
1.1激活函数:ReLU函数
传统的神经网络普遍使用Sigmoid或者tanh等非线性函数作为激活函数,然而它们容易出现梯度弥散或梯度饱和的情况。以Sigmoid函数为例,当输入的值非常大或者非常小的时候,值域的变化范围非常小,使得这些神经元的梯度值接近于0(梯度饱和现象),如图1(a)所示。由于神经网络的计算本质上是矩阵的连乘,一些近乎0的值在连乘计算中会越来越小,导致网络训练中梯度更新的弥散现象,即梯度消失。
相较于其它激活函数,ReLU函数在第一象限的近似函数:y=x,不会出现值域变化小的问题。ReLU函数直到现在也是学术界和工业界公认的最好用的激活函数之一,在各种不同的领域和模型中,ReLU函数都得到了广泛的应用。ReLU函数曲线如图1(b)所示。
![图片[1]-AlexNet:深度学习崛起的标志-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240218181640129.png)
1.2丢弃法(Dropout)
为了防止网络在训练过程中出现的过拟合现象,引入了丢弃法。过拟合现象的出现通常有两个原因:一是数据集太小;二是模型太复杂。可以用一个生活中的例子来解释过拟合的原因:高三的时候,老师提供了一个小规模的题库用于练习,并告知期末考试的题目都是从这个题库中抽出来的。但是,这个题库的题量非常少,且都是选择题,那么这时候想要期末考高分的最快捷方法是什么呢?实际上,不是理解每道题目并学会解答,单纯地背答案就够了!
所以模型也是一样的,当数据太小时,模型就不会去学习数据中的相关性,不会尝试去理解数据,提取特征。最便捷的一种方式是把数据集中的所有数据强行记忆下来,这就叫过拟合。可以想象,一个过拟合的模型是没有举一反三的能力的,即对数据的泛化能力太差,只能处理训练数据集中的数据,一旦遇到新的类似数据,模型的处理能力就会很差。
那如何解决这个问题呢?以下提供两个解决方案:
(1)提升数据集容量:让模型难以记忆所有的数据,这时候模型就会尝试学习数据、理解数据了,因为相较于记忆所有数据,这是种更容易的解决方案。
(2)把模型变得简单些:模型会选择记忆数据一方面是因为模型太复杂,有能力去记忆所有数据。当降低模型的复杂度时,就不会出现过拟合现象。总之,过拟合的本质就是数据集与模型在复杂度上不匹配。
在神经网络中Dropout是通过降低模型复杂度来防止过拟合现象的,对于某一层的神经元,通过一定的概率将某些神经元的计算结果乘0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。完整网络如图2(a)所示,Dropout过程如图2(b)所示。
![图片[2]-AlexNet:深度学习崛起的标志-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240218182053522.png)
1.3数据增强
神经网络算法是基于数据驱动的,因此,有一种被广泛认同的观点认为神经网络是靠大量数据训练出来的。如果提供海量数据进行训练,可以有效提升算法的准确率,避免过拟合,进一步增大和加深网络结构。而当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。
图像数据的变换方式有很多,其中最简单、通用的包括水平翻转图像、从原始图像中随机裁剪和平移变换以及颜色和光照变换等,这些变换方式如图3所示。
![图片[3]-AlexNet:深度学习崛起的标志-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2023/11/20231105142258339.png)
1.4多GPU实现
AlexNet当时使用了型号为GTX580的GPU进行训练,由于单个GTX 580 GPU只有3GB内存,限制了在其上可训练的网络的最大规模。为了解决这个问题,他们将模型拆分成两部分,分别放入两个GPU中进行训练。在训练过程中,两个硬件中的子网络通过交换特征图进行信息交流,从而大大加快了AlexNet的训练速度。当时,这种方式纯属硬件限制的无奈之举。但是,现在看来,这种拆分模型的训练方式与现代的一种卷积变体,组卷积(Group Convolution)非常相似。笔者认为,这也是AlexNet效果好的一个主要原因,算是无心插柳柳成荫了。
2.局部响应归一化
局部响应归一化(Local Response Normalization,LRN)技术主要用于提高深度学习训练的准确性。一般来说,LRN是在激活和池化之后进行的一种处理方法。这个归一化技术最早是在AlexNet模型中被提出的。通过实验证明它可以提高模型的泛化能力,但是提升的能力有限。后来这种方法逐渐被弃用,有些人甚至认为它是一个“伪命题”,因此备受争议。如今,批数据标准化已经成为了局部归一化的主流替代方法。
下面简要介绍一下局部归一化的灵感来源:LRN的基本思想是模拟侧抑制效应,该效应是生物神经系统的一种现象,即一个活跃的神经元会抑制其邻近神经元的活跃度。在 CNN 中,通常通过在每个小批量样本上沿深度维度进行归一化实现。也就是说,一个特定的神经元的输出将被它的“邻居”神经元的活跃度所规范化。
实验总结:由于LRN模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,从而使响应较大的值更大,提高了模型的泛化能力。在ImageNet实验中,深度学习之父Geoffrey Hinton等人使用LRN技术分别提升了模型1.4%和1.2%的准确率。然而,随后的研究并不太认可这项技术,以至于它至今仍然是一个争议性的技术,很少被使用。
2.1AlexNet代码
我们分别使用pytorch和tensorflow两种主流的深度学习框架对AlexNet的模型结构进行复现,并给出详细的代码注释,详见项目仓库












暂无评论内容