

0.引言
Swin Transformer是2021年微软研究院发表在ICCV(International Conference on Computer Vision)上的一篇文章,并且已经获得ICCV 2021最佳论文(Best Paper)的荣誉称号。Swin Transformer网络是Transformer模型在视觉领域的一次重要尝试。该模型在多项视觉任务中都有卓越的表现。Swin Transformer的设计借鉴了Vision Transformer模型对图片的处理方法。作者的初衷是让Swin Transformer能够像卷积神经网络一样分成多个模块,从而实现层级式的特征提取,使得提取出的特征具有多尺度的概念。
直接将标准Transformer应用于视觉领域存在一些问题,主要是尺度不一和高分辨率的图像所带来的计算复杂度问题。例如,在一张街景的图片中,有许多不同大小的车辆和行人,这种尺度差异的情况在自然语言处理中并不存在。此外,高分辨率图像会导致序列长度急剧增加,进而增加计算复杂度。为了解决这些问题,研究人员尝试了许多方法,包括将卷积提取到的特征图作为Transformer的输入、将图像分成多个Patch以降低分辨率或将图像分割成小窗口等。Swin Transformer采用了移动窗口的方法来学习特征。移动窗口不仅带来了更大的效率,同时由于自注意力机制是在窗口内进行计算的,可以大大降低序列长度,进而使得Swin Transformer可以处理高分辨率图像。此外,通过移动(Shifting)操作,相邻的两个窗口之间可以进行交互,从而使得上下层之间具有交叉窗口连接,从而达到全局建模的效果。
Swin Transformer的层级式结构不仅可以灵活地提供各种尺度的信息,也可以降低模型计算复杂度,使得Swin Transformer成为可以处理极大分辨率的预训练模型。
论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
下载地址:https://arxiv.org/pdf/2103.14030.pdf
视频讲解:https://www.aideeplearning.cn/mcv_lesson/978/
1.网络整体框架
先来简单对比下Swin Transformer和之前讲解的ViT模型, Swin Transformer如图1(a)所示, ViT如图1(b)所示。
![图片[1]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214104641389.png)
通过对比至少可以看出两点不同:
1.Swin Transformer模型使用了类似卷积神经网络中的层次化构建方法(Hierarchical Feature Maps),例如它的特征图尺寸中包括下采样4倍、8倍和16倍的特征图。这种设计有助于网络提取更高级别的特征,使得它更适合用于目标检测、实例分割等任务。而在之前的ViT模型中,网络一开始就直接下采样16倍,且在后面的特征图中也维持着这个下采样率不变。
2.Swin Transformer使用了Windows Multi-Head Self-Attention(W-MSA)的概念。例如,当下采样率为4倍和8倍时,特征图被划分成了多个不相交的窗口(Window),而窗口并不是最小的计算单元,最小的计算单元是窗口内的Patch块。每个窗口内都有m×m个Patch块,Swin Transformer的原论文中m的默认值为7,因此每个窗口内有49个Patch。自注意力计算都是分别在窗口内完成的,所以序列长度永远都是49(而ViT中是14×14=196的序列长度)。尽管通过基于窗口的方式计算自注意力有效地解决了内存和计算量的问题,但窗口与窗口之间没有进行通信,从而限制了模型的能力,无法达到全局建模的效果。因此,在论文中,作者提出了Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过这种方法可以使信息在相邻的窗口之间传递,这将在后面进行详细讨论。
简单看下原论文中给出的关于Swin Transformer网络的结构图,如图2(a)所示。首先将图片输入到Patch Partition模块中进行分块,即每4×4相邻的像素为一个Patch,然后在通道维度上展平。假设输入的是RGB三通道图片,那么每个Patch就有4×4=16个像素,然后每个像素有R、G、B三个值所以展平后数据维度是16×3=48,所以通过Patch Partition后图像张量的形状由[H,W,3]变成了[H/4,W/4,48]。然后再通线性嵌入层对每个像素的通道数据做线性变换,由48变成C,即图像张量的形状再由 [H/4,W/4,48]变成了[H/4,W/4,C]。其实在源码中Patch Partition和线性嵌入操作就是直接通过一个卷积层实现的,和之前ViT模型中的Embedding层结构一模一样。
![图片[2]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214104752781-1024x306.png)
接下来,Swim Transformer模型通过四个Stage构建不同尺寸的特征图。Stage1先通过一个Linear Embedding层,而剩下的三个Stage都会先使用Patch Merging层进行下采样。然后重复堆叠Swin Transformer Block,注意这里的Block实际上有两种结构,如图2(b)所示,它们的不同之处仅在于一个使用W-MSA结构,另一个使用SW-MSA结构。这两种结构是成对使用的,先使用一个W-MSA结构,然后使用一个SW-MSA结构,因此堆叠Swin Transformer Block的次数都是偶数。最后,分类网络会接上一个LN层、全局池化层以及全连接层,以得到最终输出。这里并未在顶层图中给出。
接下来将详细介绍Patch Merging、W-MSA、SW-MSA以及使用到的相对位置偏置(Relative Position Bias)。需要注意的是,Swin Transformer Block中的MLP结构和Vision Transformer中的结构是一样的,因此在这里不再赘述。
2. Patch Merging详解
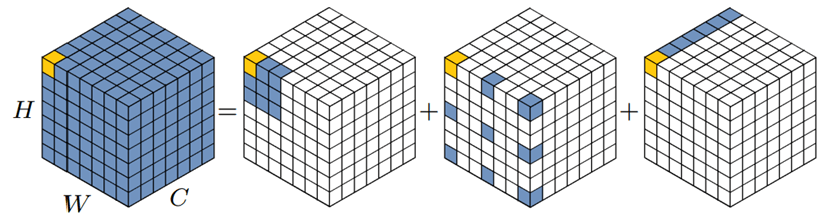
如第1节所述,在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage 1除外),此操作的目的是将特征信息从空间维度转移到通道维度。假设输入Patch Merging的是一个4×4大小的单通道特征图,以特征图左上角的四个元素为起点,通过间隔采样得到四个子特征图,然后将这四个子特征在通道维度上进行拼接,再通过一个LN层。最后通过一个全连接层在特征图的深度方向做线性变换,将特征图的深度由C变成C/2。间隔采样过程如下动图所示,拼接过程如图3所示。通过这个简单的例子可以看出,经过Patch Merging层后,特征图的高和宽会减半,深度会翻倍。
![图片[3]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214104927732.gif)
![图片[4]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214105016409.png)
3. W-MSA详解
引入W-MSA模块是为了减少计算量。普通的MSA模块如图4(a)所示,对于特征图中的每个像素,在自注意力计算过程中需要和所有的像素去计算。W-MSA模块如图4(b)所示,在使用W-MSA模块时,首先将特征图按照M×M的大小划分成一个窗口(例子中的M=4),然后单独对每个Windows内部进行自注意力计算。
![图片[5]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214105130433.png)
两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了Softmax函数的计算复杂度:
\(\begin{aligned}\Omega(\mathrm{MSA})&=4hwC^2+2(hw)^2C\\\Omega(\mathrm{W~}-\mathrm{MSA})&=4hwC^2+2M^2hwC\end{aligned}\)
其中,h代表feature map的高度,w代表feature map的宽度,C代表feature map的深度,M代表每个窗口的大小。假设特征图的h、w都为64,M=4,C=96。采用多头注意力(MSA)模块的计算复杂度为4×64×64×962+2×(64×64)2×96=3372220416,而采用W-MSA模块的计算复杂度为4×64×64×962+2×42×64×64×96=163577856,节省了95%的计算复杂度。
4. SW-MSA详解
如第3节所述,使用W-MSA模块时,只会在每个窗口内进行自注意力计算,因此窗口与窗口之间无法进行信息传递。为了解决这个问题,作者引入了SW-MSA模块,即进行偏移的W-MSA,如图5所示。计算自注意力机制前,窗口发生了偏移,可以理解成窗口从左上角分别向右侧和下方各偏移了M/2个像素。
在此情况下,观察图5展示的Layer1+1层可以发现,对于第一行第二列的2×4窗口,它可以使Layer1层第一排的两个4×4大小的窗口之间进行信息进行交流。同样的道理,对于Layer1+1第二行第二列的4×4窗口,它可以促进Layer1层中四个窗口之间的信息交流。其他窗口的情况也是如此。这解决了不同窗口之间无法进行信息交流的问题。
![图片[6]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214105533442.png)
观察图5,可以发现将窗口进行偏移后,窗口之间实现了信息的交互。但原始的特征图仅包含4个窗口,经过移动窗口后,窗口数量增加到了9个,而且这9个窗口的大小并不完全相同,导致了计算难度的增加。因此,作者提出了一种更加高效的计算方法,Efficient Batch Computation for Shifted Configuration,如图6所示。
先将 “012”区域移动到最下方,再将 “360”区域移动到最右方,此时移动完后,区域“4”成为了一个单独的窗口,再将区域“5”和“3”合并成一个窗口;“7”和“1”合并成一个窗口;“8”、“6”、“2”和“0”合并成一个窗口。这样又和原来一样变为4个4×4的窗口了,就能够保证计算量的一致,然后分别在每个窗口内进行自注意力计算操作来提取特征,这样可以更有效地利用GPU并行计算的加速效果。但是把不同的区域合并在一起(比如5和3)进行MSA,从逻辑上讲是不合理的,因为这两个区域并不应该相邻。为了防止这个问题,在实际计算中使用的是带蒙板的MSA(Masked MSA),这样就能够通过设置蒙板来隔绝不同区域的信息了。关于蒙版如何使用,先回顾常规的MSA计算过程:
\(\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^\mathrm{T}}{\sqrt{d_k}})V\)
可以发现,其在最后输出时要经过Softmax操作,Softmax在输入很小时,其输出几乎为0。以图6的区域“5”和区域“3”合并后的区域“53”为例,如果某像素是属于区域5的,我们只想让它和区域“5”内的像素进行匹配。为了实现这个目标,可以将该像素与区域“3”中的所有像素进行注意力计算时,将计算结果减去100。这样,在经过Softmax之后,对应的权重就会接近于0。因此,对于该像素而言,实际上只与区域“5”内的像素进行了MSA。对于其他像素也是同理。需要注意的是,在计算结束后,还需要将数据移回到原来的位置上。
![图片[7]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214105717710.png)
5.相对位置偏置详解
关于相对位置偏置,原论文中指出使用该技术能够带来明显的性能提升。根据实验结果,在ImageNet数据集上,如果不使用任何位置偏置,Top-1准确率为80.1,但使用相对位置偏置后,Top-1准确率为83.3,提升效果明显。相对位置偏置的添加方式如下:
\(\operatorname{At\text{tention}} ( Q , K , V ) = \operatorname { softmax }(\frac{QK^\mathrm{T}}{\sqrt d}+B)V\)
要理解相对位置偏置,应先理解什么是相对位置索引和绝对位置索引。如图7所示,首先我们可以构建出每个像素的绝对位置(左上方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的。比如蓝色的像素对应的是第0行第0列,所以绝对位置索引是(0,0),接下来再看看相对位置索引。以蓝色的像素举例,用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。例如黄色像素的绝对位置索引是(0,1),则它相对蓝色像素的相对位置索引为(0,0)-(0,1)=(0,-1)。那么同理可以得到其他位置相对蓝色像素的相对位置索引矩阵。同样,也能得到相对黄色,红色以及绿色像素的相对位置索引矩阵。接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的4×4矩阵。
![图片[8]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240214110114802.png)
请注意,到目前为止,计算得到的是二维的相对位置索引,并不是相对位置偏置参数。相对位置偏置是一维的可学习参数,会跟随网络进行自我更新。可以根据相对位置索引来获取对应的相对位置偏置参数。如图8的红框位置所示,在绝对位置中,黄色像素在蓝色像素的右侧,所以黄色像素相对于蓝色像素的相对位置索引为(0,-1);在绝对位置中,绿色像素在红色像素的右侧,所以绿色像素相对于红色像素的相对位置索引也为(0,-1)。根据偏置参数表,这两个相对位置索引对应的相对位置偏置参数均为0.4,其他偏置参数获取方式同理。
![图片[9]-Swin Transformer:窗口化的Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240224183625801.png)
在Swin Transformer中,相对位置索引能够提供比绝对位置索引更好的性能,主要有以下几个原因:
(1)更强的空间感知能力:相对位置索引可以更好地捕捉图像中像素之间的空间关系。相比之下,绝对位置索引只能表达每个像素在整个图像中的位置,而不能表达像素之间的相对位置关系。在处理图像这种具有明显空间关系的数据时,像素之间的相对位置关系往往比它们在整个图像中的绝对位置更重要。
(2)更好的泛化能力:相对位置索引对输入数据的大小和形状更具有鲁棒性。由于相对位置索引只关心像素之间的相对位置关系,因此即使输入图像的大小或形状发生改变,模型也可以很好地处理。相比之下,绝对位置索引需要对每种大小和形状的图像都进行单独的编码,这可能限制了模型的泛化能力。
(3)更好的对齐能力:在Swin Transformer的设计中,每个Transformer层的窗口都会进行一定的移位。这种设计使得每个像素都能在不同的窗口中,从而能接触到更广泛的上下文信息。相对位置索引可以很好地适应这种窗口移位操作,因为它只关心像素之间的相对位置关系。相比之下,绝对位置索引可能在这种窗口移位操作下面临困难,因为它需要对每个窗口进行单独的位置编码。
因此,相对位置索引在Swin Transformer中通常能够提供比绝对位置索引更好的性能。
6. Swin Transformer模型详细配置参数
原论文中给出的关于不同Swin Transformer的配置:T(Tiny)、S(Small)、B(Base)、L(Large)见表1。其中:“win. sz. 7×7”表示使用的窗口的大小。dim表示特征图的通道深度(或者说Token的向量长度),head表示多头注意力模块中注意力头的个数。
| downsp.rate (output size) | Swin-T | Swin-S | ||||
| stage 1 | 4× (56×56) | concat 4×4,96-d.LN | concat 4×4.96-d.LN | |||
| win.sz.7×7, dim 96.head 3 | ×2 | win.sz.7×7, dim 96,head 3 | × 2 | |||
| stage 2 | 8× (28×28) | concat 2×2,192-d,LN | concat 2×2,192-d,LN | |||
| win.sz.7×7. dim 192, head 6 | ×2 | win.sz.7×7. dim 192, head 6 | ×2 | |||
| stage 3 | 16× (14×14) | concat 2×2.384-d,LN | concat 2×2.384-d,LN | |||
| win.sz.7×7, dim 384,head 12 | ×6 | win.sz.7×7, dim 384,head 12 | × 18 | |||
| stage 4 | 32× (7×7) | concat 2×2.768-d,LN | concat 2×2,768-d,LN | |||
| win.sz.7×7. dim 768,head 24 | × 2 | win.Sz.7×7. dim 768,head 24 | × 2 | |||
| downsp.rate (output size) | Swin-B | Swin-L | ||||
| stage 1 | 4× (56×56) | concat 4×4.128-d.LN | concat 4×4.192-d.LN | |||
| win.sz.7×7, dim 128,head 4 | × 2 | win.sz.7×7, dim 192,head 6 | ×2 | |||
| stage 2 | 8× (28×28) | concat 2×2.256-d,LN | concat 2×2.384-d,LN | |||
| win.sz.7×7. dim 256,head 8 | × 2 | win.sz.7×7. dim 384,head 12 | ×2 | |||
| stage 3 | 16× (14×14) | concat 2×2.512-d,LN | concat 2×2.768-d,LN | |||
| win.sz.7×7, dim 512,head 16 | × 18 | win.sz.7×7 dim 768,head 24 | × 18 | |||
| stage 4 | 32× (7×7) | concat 2×2,1024-d,LN | concat 2×2,1536-d,LN | |||
| win.sz.7×7. dim 1024,head 32 | ×2 | win.Sz.7×7. dim 1536,head 48 | ×2 | |||
7. Swin Transformer模型讨论与总结
实际上,笔者认为Swin Transformer模型可以被视为一种优化版的CNN模型,是一种披着Transformer外壳的CNN。其主要的优化在于用局部Patch的自注意力机制替代了CNN的卷积。在模型设计思想上,Swin Transformer处处都在模仿CNN,例如:Window的机制类似于卷积核的局部相关性。层级结构的下采样类似于CNN的层级结构。Window的Shift操作类似于卷积的non-overlapping的步长。因此,虽然Transformer模型在计算机视觉领域占据了一定的地位,但也不应该忽视卷积的重要性。在计算机视觉领域自注意力不会替代卷积操作,而是和卷积操作融合,取长补短。例如,图像和文本的一个显著区别在于图像比文本维度更大,因此直接使用自注意力会导致计算量异常庞大,这显然不是我们所期望的。为了缓解这个问题,可以借鉴卷积神经网络的局部特征提取思想,或者干脆在网络的前几层使用卷积。例如,ViT模型将图片分成多个无重叠的Patch,每个Patch通过线性映射操作映射为Patch embedding,这个过程其实就是卷积。
卷积操作有两个假设:局部相关性和平移不变性。被认为是卷积操作在计算机视觉领域如此有效的原因之一,因为这两个假设与图像的数据分布非常匹配。这样,我们可以尝试将这两个假设和自注意力机制结合起来,即自注意力计算不是针对全局的,而是类似卷积一样,一个Patch一个Patch滑动,每个Patch里做自注意力计算,这就是Swin Transformer的思路。
此外,我们面对一个领域内多种方法的时候,通常会想要对它们的优劣进行排序。然而实际上,这种做法是没有必要的,因为每个方法都有其适用的范围,也都有其优缺点。因此,我们应该拥有更为开放和包容的心态,不要在不知道具体数据分布的情况下强行进行排序,也不要盲目接受他人的排序。只有当数据分布被确定之后,才能分析已有方法的特性,以确定哪种方法与之相匹配,最终将这些方法的优点集于一身,岂不美哉?
在深度学习火爆的时候,许多初学者会内心疑惑:“既然有了深度学习,是否还需要传统机器学习算法?”笔者在前文中讨论过这个问题:“尺有所长,寸有所短。”每个模型都有它适用的范围,深度学习也不例外。例如,你的数据天然是线性可分的,那SVM将会是最好的选择,如果你选了“高大上”的深度学习,结果反而会适得其反。面对一个任务,分析这个任务的需求,然后在武器库(也就是各种模型)里寻找跟这个需求匹配的武器,知己知彼,方能百战不殆。不要瞧不起SVM这样的“匕首”,也不要太高看深度学习这样的“屠龙刀”。














暂无评论内容