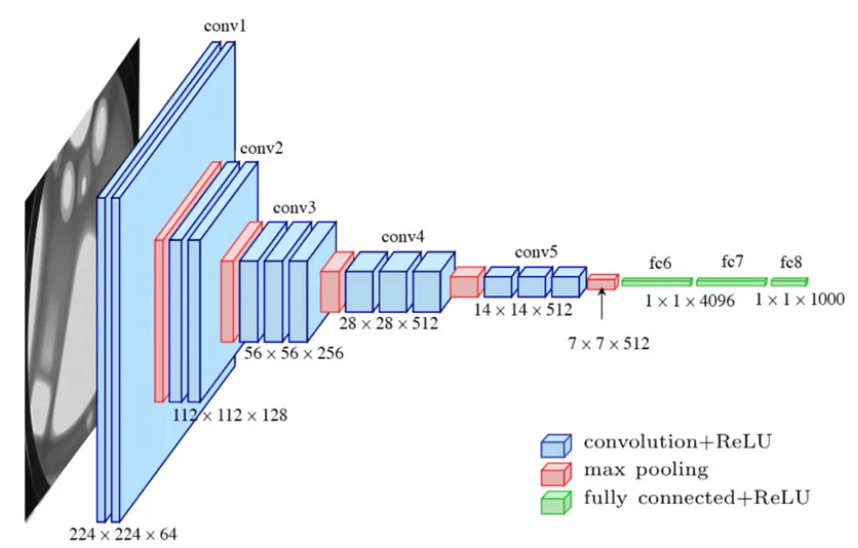



1.VGGNet模型总览
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员Karen Simonyan和Andrew Zisserman研发出了新的深度卷积神经网络:VGGNet,并在ILSVRC2014比赛分类项目中取得了第二名的好成绩(第一名是同年提出的GoogLeNet模型),同时在定位项目中获得第一名。
VGGNet模型通过探索卷积神经网络的深度与性能之间的关系,成功构建了16~19层深的卷积神经网络,并证明了增加网络深度可以在一定程度上提高网络性能,大幅降低错误率。此外,VGGNet具有很强的拓展性和泛化性,适用于其它类型的图像数据。至今,VGGNet仍然被广泛应用于图像特征提取。
VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
论文名称:Very Deep Convolutional Networks for Large-scale Image Recognition 。
下载地址:https://arxiv.org/pdf/1409.1556.pdf
视频讲解:https://www.aideeplearning.cn/mcv_lesson/774/
经典的VGG-16网络模型如图1所示。模型接收的输入是彩色图像,数据存储的形状为(B, C, H, W),B表示图像数量,C表示图片色彩通道,H表示图片高度,W为图片宽度)。在本示例中,输入数据为(1, 3, 224, 224)
模型的特征提取阶段是通过不断重复堆叠卷积层和池化层来实现的。一共经过5次下采样(图中红颜色的层结构),下采样方式为最大池化。值得注意的是,通过调整步长和填充,网络中的所有卷积操作都没有改变输入特征图的尺寸。
在最后的顶层设计中,通过三个全连接层实现对图片的分类操作。值得注意的是,由于全连接层的存在,网络只能接收固定大小的图像尺寸。
![图片[1]- VGGNet: 探索深度的力量-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240218192107792.png)
2.网络贡献总结
2.1结构简洁
VGG网络中,所有卷积层的卷积核大小,步长和填充都相同,并且通过使用最大池化对卷积层进行分层。所有隐藏层的激活单元都采用ReLU函数。在最后的顶层设计中,通过三层全连接层和Softmax分类器输出层实现对图像的分类操作。由于其极简且清晰的结构,VGGNet至今仍广泛用于图像特征提取。
2.2小卷积核
VGGNet中所有的卷积层都使用了小卷积核(3×3)。这种设计有两个优点:一方面,可以大幅减少参数量;另一方面,节省下来的参数可以用于堆叠更多的卷积层,进一步增加了网络的深度和非线性映射能力,从而提高了网络的表达和特征提取能力。
小卷积核是VGGNet的一个重要特点,虽然VGGNet是在模仿AlexNet的网络结构,但并没有采用AlexNet中比较大的卷积核尺寸(如7×7),而是通过降低卷积核的大小(3×3),增加卷积子层数来达到同样的性能。
VGG模型中指出两个3×3的卷积堆叠获得的感受野大小,相当于一个5×5的卷积;而3个7×7卷积的堆叠获取到的感受野相当于一个7×7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如5×5的参数为25个,而2个3×3的参数为18)。
卷积计算结果尺寸(卷积后特征图的size)的计算方式如下:
输入的特征图尺寸为 $i$, 卷积核的尺寸为 $k$, 步长 (Stride) 为 $s$, 填充 (Padding) 为 $p$,则输出的特征图的尺寸 $o$ 为:
o=\left[\frac{i+2 p-k}{s}\right]+1假设特征图是28×28的,假设卷积的步长step=1, padding=0。
(1)使用一层5×5卷积核,由(28-5)/1+1=24可得,输出的特征图尺寸为24×24。
(2)使用两层3×3卷积核:第一层,由(28-3)/1+1=26可得,输出的特征图尺寸为26×26;第二层,由(26-3)/1+1=24可得,输出的特征图尺寸为24×24。
可以看到最终结果两者相同,即两个3×3的卷积堆叠获得的感受野大小,相当于一个5×5的卷积。
2.3小池化核
相比AlexNet的3×3的池化核,VGGNet全部采用2×2的池化核。
2.4通道数多
VGGNet第一层的通道数为64,后面每层都进行了翻倍,最多达到512个通道。相比较于AlexNet和ZFNet最多得到的通道数是256,VGGNet翻倍的通道数使得更多的信息可以被卷积操作提取出来。
2.5层数更深、特征图更多
网络中,卷积层专注于扩大特征图的通道数、池化层专注于缩小特征图的宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
3.VGGNet模型小结
VGGNet是于2014年提出的经典卷积神经网络模型。VGG网络结构简单而规整,由一系列重复的卷积块(Conv Block)和池化块(Pool Block)构成。每个卷积块包含若干个卷积层和激活函数,每个池化块则包含一个池化层。所有的卷积层和池化层都使用相同的卷积核尺寸和步长,从而使得网络结构规整。
此外,VGGNet采用了较小的卷积核尺寸(通常为3×3),这样可以减少模型参数数量,并且通过堆叠多层卷积层来增加模型的深度,从而提高模型的表达能力和分类准确率。在池化层中,VGGNet使用最大池化(Max Pooling)来减少特征图的大小。
VGGNet有多个版本,包括VGG-16、VGG-19等。其中VGG-16包含13个卷积层和3个全连接层,其中VGG-19包含16个卷积层和3个全连接层。这些版本的VGGNet都在ImageNet图像分类竞赛中取得了优异的成绩,并成为了图像分类任务中的经典模型之一。
4.VGGNet代码
我们分别使用pytorch和tensorflow两种主流的深度学习框架对VGGNet的模型结构进行复现,并给出详细的代码注释,详见项目仓库












暂无评论内容