

1.EfficientNetV1
EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks。从标题中可以看出,这篇论文最主要的创新点是模型缩放。论文提出了一种被称为混合缩放(Compound Scaling)的方法,通过在模型的深度、宽度和分辨率这三个方面按一定比例进行缩放,来提高网络的效果。在网络变得更大的情况下,EfficientNet可以显著提升精度上限,并成为当时最强大的网络之一。EfficientNet-B7在ImageNet上获得了最先进的84.4%的准确率,参数量上比之前最好的卷积网络(谷歌公司提出的GPipe, Top-1: 84.3%, Top-5: 97.0%)小了8.4倍,速度提升6.1倍。
论文地址:https://arxiv.org/abs/1905.11946
视频讲解:https://www.aideeplearning.cn/mcv_lesson/974/
1.1EfficientNet V1模型设计动机
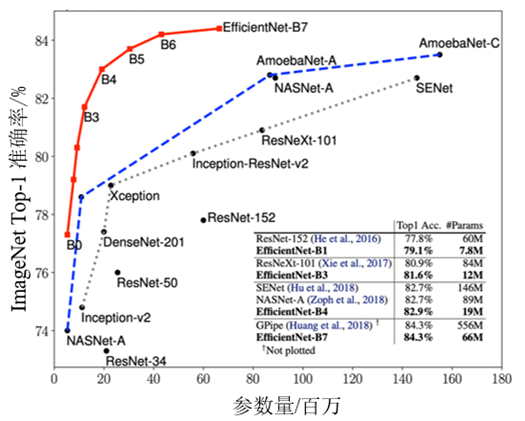
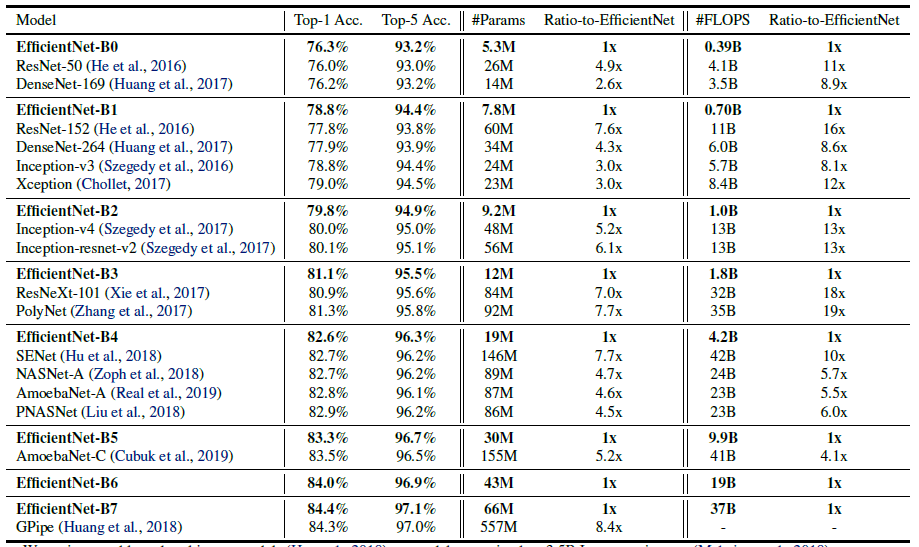
EfficientNet的主要创新点并不是网络层级结构。与发明了残差连接的ResNet或通道注意力机制的SENet不同,EfficientNet的网络层级结构与MobileNet V3类似,都是利用NAS网络搜索技术获得的,然后使用混合缩放规则进行放缩,得到一系列表现优异的网络:从EfficientNet-B0到EfficientNet-B7。ImageNet的Top-1准确率与参数量和FLOPs之间的变化关系如图1所示,可以看到EfficientNet饱和值高,并且具有快速的训练速度。
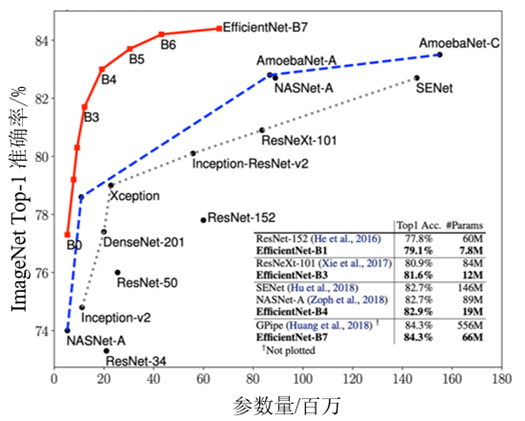
图1 模型准确率对比
如果有足够的数据并且过拟合不会成为问题,增加网络参数可以提高模型精度。例如ResNet可以从ResNet-18加深到ResNet-200,GPipe将基线模型放大四倍在ImageNet数据集上获得了84.3%的top-1精度。增加网络参数的方式有三种:增加网络深度、宽度和提高输入图像的分辨率。探究这三种方式对网络性能的影响,以及如何同时缩放这三个因素是EifficentNet的主要贡献。
1.2模型的三种缩放方法
放大网络的策略如图2所示,其中:参照网络如图2(a)所示;放大网络的宽度方法如图2(b)所示;放大网络的深度方法如图2(c)所示;放大网络的输入尺寸方法如图2(d)所示;EfficientNet的策略,同时缩放宽度、深度和输入信息尺寸方法如图2(e)所示。
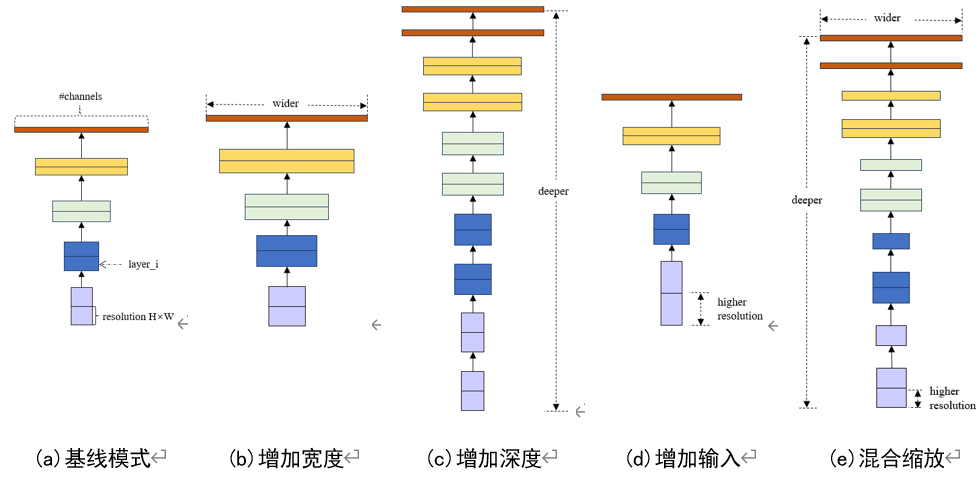
图2 模型缩放方法
对三种网络策略做详细解释:
(1)放大网络的深度:在许多模型中,如VGGNet和ResNet,缩放网络深度是一种常见的方式。更深的网络可以捕获到更丰富和更复杂的特征,在新任务上也可以泛化得更好。然而,更深的网络也面临梯度不稳定性问题和网络退化问题,这使得训练变得更加困难。尽管有一些技术,例如跨层连接、批量归一化等可以有效减缓这些训练问题,但是深层网络的精度回报确实减弱了。例如,ResNet-1000和ResNet-101具有类似的精度,即使ResNet-1000的层数更多。
(2)放大网络的宽度:缩放网络宽度也是一种常用方法,具体来说就是让每次卷积操作输出的特征图多一些。例如GoogLeNet系列网络,正如之前讨论的,更宽的网络可以捕捉到更细粒度的特征,从而易于训练。然而,非常宽而又很浅的网络在捕捉高层次特征时有困难。
(3)放大网络的输入尺寸:使用更高分辨率的输入图像,卷积网络可能捕捉到更细粒度的模式。最早使用的是224×224像素的输入图像,现在有些模型为了获得更高的精度选择使用384×384或者448×448像素的输入图像。
但是,这里单独加深某一种策略,所得到的精度回报都不是成正比的,如图3所示。
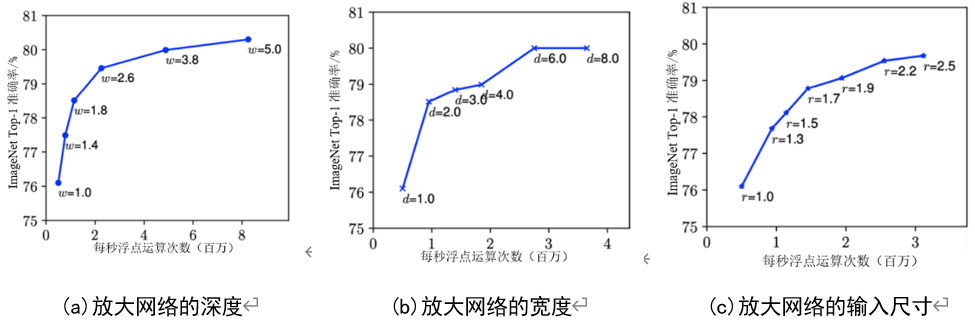
图3 单独加深一种策略对模型准确率的影响
三种策略显示着同一规律:刚开始时可以有效提高模型准确度,然后逐渐趋于饱和,而且所得到的准确度回报越来越少。
1.3EfficientNet V1模型的缩放比率
根据经验,我们观察到三种缩放策略之间并不是独立的。直观上来讲,对于分辨率更高的图像,应该增加网络深度,因为需要更大的感受野来帮助捕获更多像素点的类似特征,同时也应该增加网络宽度来获得更细粒度的特征。这些直觉指导着我们去协调平衡不同缩放维度,而不是只是单一地缩放某个维度。
为了追求更好的精度和效率,在缩放时平衡网络所有维度至关重要。事实上,之前的一些研究已经开始探索任意缩放网络深度和宽度的方法,但是它们仍然需要复杂的人工微调。在此论文中提出了一种新的复合缩放方法——使用一个复合系数Φ来统一缩放网络宽度、深度和分辨率,详见下面的公式1。
\(\begin{gathered}
\mathrm{depth:d}=\alpha^{\Phi} \\
\mathrm{width:w=\beta^{\Phi}} \\
\mathrm{resolution:r=\gamma}^{\Phi} \\
\mathrm{s.t.}\alpha\cdot\beta^{2}\cdot\gamma^{2}\approx2 \\
\alpha\geq1,\beta\geq1,\gamma\geq1
\end{gathered}\)
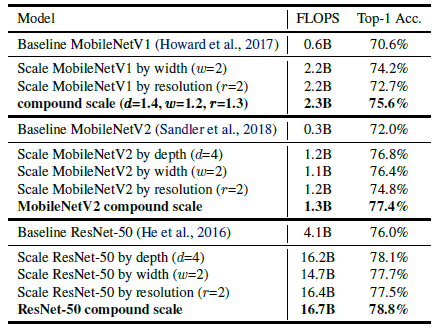
其中α、β和γ是通过NAS网络搜索技术得到的,具体缩放因子在MobileNet V1、MobileNet V2和ResNet-50网络上的提升效果见表1。
表1复合系数ϕ对网络的影响
1.4EfficientNet V1模型结构
EfficientNet的模型结构设计参考了MobileNet系列网络的构建方法,并采用了NAS技术进行搜索。这种结构的搜索方法突出的一个“有钱就是任性”。同时,EfficientNet引入了MobileNet V3中的MBConv作为模型的主干网络,并借鉴了SENet中的Squeeze-and-Excitation方法进一步提升性能。由于使用的NAS搜索空间相似,得到的网络结构也很相似。
EfficientNet V1完整的网络模型架构参数见表2。
表2 模型结构细节
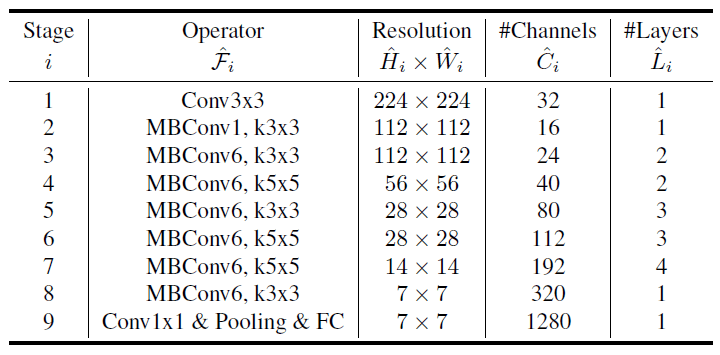
如表2所示,EfficientNet-B0模型其实就是由简单的MBconv操作堆叠而成的。对于EfficientNet-B0这样的一个基线网络,如何进行模型大小的缩放?原文中给出答案。
(1)步骤1:首先固定Φ,根据公式2和1并在\(\alpha\cdot\beta^2\cdot\gamma^2\approx2\)的约束条件下,EfficientNet-B0的最佳值是\(\alpha=1.2,\beta=1.1,\gamma=1.15\)。其中公式2为:
\(\begin{gathered}
\max_{\mathrm{d,w,r}}\mathrm{Accuracy}(\mathcal{N}(\mathrm{d,w,r})) \\
\mathrm{s.t.~}\mathcal{N}(\mathrm{d,w,r})=\operatorname*{\odot}_{\mathrm{i=1\cdots s}}\widehat{\mathcal{F}_{1}^{\mathrm{d\cdot\widehat{L_{1}}}}}(\mathrm{X}_{\left\langle\mathrm{r\cdot\widehat{H_{1}},r\cdot\widehat{W_{1}},r\cdot\widehat{C_{1}}}\right\rangle}) \\
Memory(N)\leq target\_memory \\
FLOPS(\mathcal{N})\leq target\_flops
\end{gathered}\)
(2)步骤2:将α、β和γ固定为常数,用公式1将基线网络扩大到不同Φ,可以得到EfficientNet-B1至EfficientNet-B7模型(详见表3)。
首先,给出了最佳缩放因子α、β和γ的具体数值,分别是1.2、1.1、1.15。 然后将α、β和γ固定为常数并按比例放大得到EfficientNet-B0~B7一共七个网络模型。具体缩放因子见表3。
表3 B0~7的缩放因子
| 模型 | 参数(width, depth, resolution, dropout_rate) |
| efficientnet-b0 | (1.0,1.0,224,0.2) |
| efficientnet-b1 | (1.0,1.1,240,0.2) |
| efficientnet-b2 | (1.1,1.2,260,0.3) |
| efficientnet-b3 | (1.2,1.4,300,0.3) |
| efficientnet-b4 | (1.4,1.8,380,0.4) |
| efficientnet-b5 | (1.6,2.2,456,0.4) |
| efficientnet-b6 | (1.8,2.6,528,0.5) |
| efficientnet-b7 | (2.0,3.1,600,0.5) |
最后,作者便由此扩展出了一系列的网络结构,见表4。
表4 基础网络缩放
1.5EifficientNet V1小结
EfficientNet V1是一种高效的深度学习卷积神经网络架构,由谷歌团队于2019年提出。它通过使用复合缩放法(Compound Scaling)平衡网络的深度、宽度和分辨率,实现了高性能和低计算复杂性的平衡。EfficientNet V1的主要特点如下:。
(1)复合缩放法:EfficientNet V1引入了一种新的缩放方法,将网络的深度、宽度和输入分辨率同时缩放。这种方法使用了两个超参数:深度乘子(α)和宽度乘子(β)。通过调整这两个参数,用户可以根据设备性能和应用场景权衡模型的精度和速度。
(2)基础网络(EfficientNet-B0):EfficientNet V1以一种基础网络(EfficientNet-B0)为起点,该网络结构采用了类似于MobileNet V2逆残差结构与SE模块。这些设计有助于提高模型性能和效率。
(3)多种缩放版本:EfficientNet V1提供了一系列不同规模的网络版本(从EfficientNet-B0到B7),以满足不同设备和应用场景的需求。较大规模的版本在保持较低计算复杂性的同时,实现了更高的性能。
总之,EfficientNet V1是一种高性能、低计算复杂性的深度学习模型,适用于各种设备和应用场景。其主要特点包括采用复合缩放法、基础网络结构、多种缩放版本,以及在多种计算机视觉任务中展现出高性能和低计算资源占用。
2.EifficentNet V2
2.1EifficentNet V2模型设计动机
首先,对于深度学习模型而言,训练效率是一个非常重要的问题,包括训练时间和训练后的模型参数大小两个方面。例如GPT3,在少样本学习方面表现出色,但是它的训练效率不高,需要数周的训练和成千上万块的GPU集群,训练成本极高。对于普通用户来说,不可能有机会参与到训练或者优化的工作中,这是目前深度学习发展的一个很大的限制。
另外,现有的渐进式学习方法通常采用逐步增大输入图像的尺寸来实现,但是保持相同的正则化配置。这是导致模型性能下降的一大因素。接下来笔者会介绍什么是渐进式学习。
因此基于上述三个动机,EfficientNet V2提出了相应的改进方案:
(1)提出了EfficientNet V2模型,谷歌在EfficientNet的基础上,引入了融合MBConv(Fused-MBConv)到搜索空间中。
(2)修改了渐进式学习策略,提出了自适应调整正则化参数的机制,实现了加速训练、同时还能够保证准确率不降,甚至还有细微上升的效果。
(3)在多个基准数据集上进行了实验,结果表明EfficientNet V2取得了与几个技术前沿模型(State-of-the-Art Systems,SOTA)相媲美的性能,且训练效率更高。
论文地址:https://arxiv.org/pdf/2104.00298
2.2EifficentNet的问题
2.2.1大图像尺寸会导致显著的内存占用
已有研究表明:输入EfficientNet的大尺寸图像会导致显著的内存占用。由于计算单元的总内存是固定的,因此不得不采用更小的批量训练这些模型,这无疑会降低训练速度。效果对比见表5,如果训练图片尺寸设置为512,就会出现内存溢出(Out Of Memory,OOM)的问题,在占满显存的前提下,不同分辨率的输入图片可设置的批量大小是不同的。
表5 不同输入分辨率下的模型计算速度

2.2.2逐层卷积不能完全利用现有的加速器
逐层卷积虽然理论上减少了很多的计算量,但它无法完全利用现有的加速器。因此,V2版本中提出了Fused-MBConv,被证明可以充分利用移动端和服务器端的加速器来加速计算。为此,EfficientNet V2将Fused-MBConv算子引入到搜索空间中,以进一步提高计算速度。
2.2.3EfficientNet的缩放策略不是最优解
EfficientNet的缩放策略是值得探讨的,因为它同时考虑了网络宽度、网络深度和分辨率,已经被证明能够提高模型性能。但是采用的策略是对模型结构均匀地缩放和扩张,这意味着每个阶段的扩展倍数都是相同的。例如,如果将深度系数配置为2,那么每个阶段的网络深度都会增加两倍。然而,作者认为这种策略并不是最佳解决方案,因为不同的阶段对于模型的训练效率和性能影响并不相同。因此,EfficientNet V2版本中对于不同的Stage采用了非均匀的模型缩放策略。
2.3EfficientNet V2的改进
有了上面的讨论,那么对于这篇论文网络架构的设计就很好理解了。
2.3.1优化NAS神经网络结构搜索
作者的主要改进包括:把Fused-MBConv算子加入到搜索空间中,移除一些不重要的搜索选项。
搜索的结果是将模型前几个Stage的MBconv替换成Fused-MBConv,详见表6。
表6 EfficientNet V2 模型架构

2.3.2详解Fused-MBConv模块
Fused-MBConv将原来的DWConv转换为标准的卷积,如图4所示。这个改变是因为根据ShuffleNet V2中的观点:尽管分组卷积看似可以减少参数量,但实际上会增加运算时间(DWConv是分组卷积的极端情况),除此之外,Fused-MBConv与MBConv在其他方面并没有明显的区别。

图4 Fused-MBConv模块结构图
2.3.3每阶段的网络缩放因子应该有所区别
在EifficentNet V1版本中,每个阶段的网络缩放倍率是相同的。然而在EifficentNet V2版本中,则有提出了新观点:针对不同的阶段应该采用不同的缩放倍率。并在论文中出了具体的网络参数。作为一种启发式方法,作者在网络的后几个阶段Stage5和Stage6阶段添加更多的层结构。并且,值得注意的是,作者将最大推理图像大小限制为480×480的分辨率,因为非常大的图像通常会导致昂贵的内存和训练速度开销。
2.3.4引入改进的渐进式学习的策略
渐进式学习是指在训练过程中,随训练时间动态地调整输入图片的尺寸,以充分利用训练数据集。然而,现有的渐进式学习方法只针对输入进行修改,而未调整模型的正则化参数,也就是未改变反向调参过程,这是否意味着不同分辨率的图片对模型的影响是同等的。
这是导致模型准确率下降的一个原因。经验表明,更大的模型应该需要更严格的正则化来避免过拟合,例如EfficientNet-B7就需要设置更大的Dropout值以及更强的数据增强方式。
因此,这篇论文认为即使对于同一个网络,更小的图片尺寸训练出的模型性能也更差,因此需要更弱的正则化要求。反之,大尺寸的图片,则需要更严格的正则化配置。因此随着训练轮数的迭代,输入模型的图像尺寸逐渐变大,同时实验配置的正则化参数也随之增大,包括Dropout的概率、随机擦除样本的行数、两种图片混合的比例(后两个是图像增强的手段)。也就是数据增强的幅度在逐渐增大,用于提高模型的正则化要求。
2.4EifficentNet V2小结
EfficientNet V2是一种高效的深度学习卷积神经网络架构,由谷歌团队在EfficientNet V1的基础上于2021年提出。它在保持高性能的同时,进一步提高了训练速度和推理效率,适用于各种设备和应用场景。EfficientNet V2的主要特点如下:
(1)更高的训练效率:相较于V1版本,EfficientNet V2在训练速度上取得了显著提升。这得益于模型结构的优化和新的训练策略,使得模型在相同的计算资源下能够更快地收敛。
(2)新的卷积模块:EfficientNet V2引入了融合MBConv模块,该模块将卷积和卷积结合在一起,以提高计算效率。同时,EfficientNet V2版本保留了EfficientNet V1中的逆残差结构和SE模块,进一步优化了网络结构。
(3)进化的复合缩放法:EfficientNet V2继承了EfficientNet V1中的复合缩放法,将网络的深度、宽度和输入分辨率同时缩放。不过,V2版本在此基础上进行了优化,使得网络在不同缩放级别上的性能更加平衡。
(4)多种缩放版本:与EfficientNet V1类似,EfficientNet V2提供了一系列不同规模的网络版本(从S到XL),以满足不同设备和应用场景的需求。较大规模的版本在保持较低计算复杂性的同时,实现了更高的性能。
总之,EfficientNet V2是一种高性能、低计算复杂性且训练速度更快的深度学习模型,适用于各种设备和应用场景。其主要特点包括更高的训练效率、新的卷积模块、进化的复合缩放法、多种缩放版本,以及在多种计算机视觉任务中展现出高性能和低计算资源占用。














暂无评论内容