

0.引言
最初提出Transformer算法是为了解决自然语言处理领域的问题,Transformer在该领域获得了巨大的成功,几乎超越了循环神经网络模型(RNN),并成为自然语言处理领域的新一代基线模型。论文Vision Transformer受到其启发,尝试将其应用于计算机视觉领域。通过实验,论文中提出的ViT模型在ImageNet数据集上取得了88.55%的准确率,表明Transformer在计算机视觉领域确实是有效的。尤其是在大数据集预训练的支持之下,Vision Transformer模型也成为了Transformer在计算机视觉领域的里程碑之一。
这篇论文通过实验展示了大型数据集的支持对Transformer模型在计算机视觉领域的性能影响,结果如图1所示。其中横轴为不同的数据集,从左往右数据集容量依次是(130万、2100万、30000万);竖轴为分类准确率,图中两条折线之间的区域代表纯卷积网络ResNet能够达到的性能范围,不同颜色的圆形代表不同大小的ViT模型。在数据集容量为100万左右时(如ImageNet-1K),ViT模型的分类准确率明显低于CNN模型(例如ResNet);而当数据集容量为2100万左右时(如ImageNet-21K),ViT模型的分类准确率与CNN模型相当;而当数据集容量达到30000万时(如JFT-300M),ViT模型的分类准确率略高于CNN模型。
论文地址:https://arxiv.org/abs/2010.11929
视频讲解:https://www.aideeplearning.cn/mcv_lesson/977/
![图片[1]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205175933242.png)
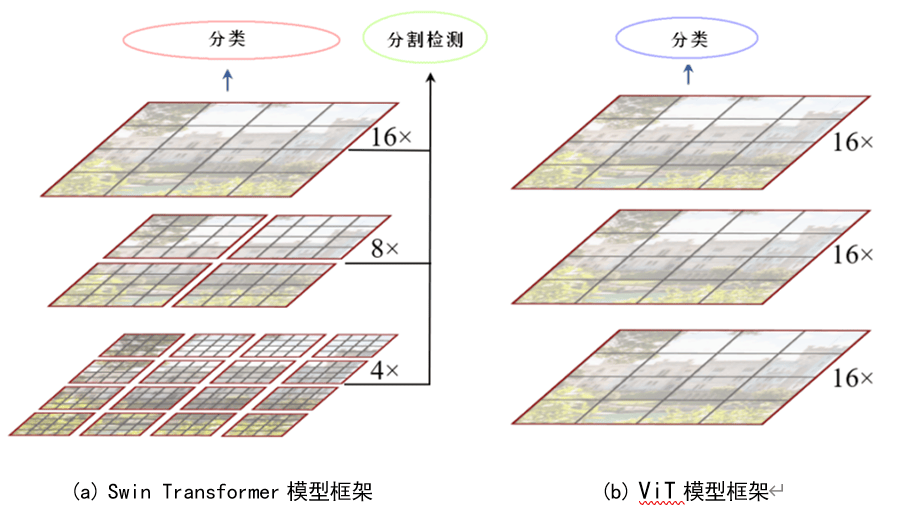
1.ViT框架
在模型设计方面,ViT尽可能地遵循原始的Transformer架构以提供一种计算机视觉和自然语言处理领域共用的大一统算法框架。因此,ViT在后续的多模态任务中,尤其是文本和图像结合的任务中,提供了许多有用的参考。在本博文中,主要比较了三种模型:ResNet、ViT(纯Transformer模型)以及Hybrid(卷积和Transformer混合模型)。
原论文中给出的关于ViT模型框架如图2所示,共三个模块:
(1)Linear Projection of Flattened Patches:嵌入层(Embedding),负责将图片映射成向量。
(2)Transformer Encoder:负责对输入信息进行计算学习。
(3)MLP Head:最终用于分类的层结构,与CNN常用的顶层设计类似。
![图片[2]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205184738908.png)
2.图片数据的向量化
对于标准的Transformer模块,要求输入的是Token序列,即二维矩阵[num_token, token_dim]。对于图像数据而言,其数据格式[H,W,C]是三维矩阵,并不是Transformer期望的格式,因此,需要先通过一个嵌入层来对数据做变换。具体来说,将分辨率为224×224的输入图片按照16×16大小的Patch进行划分,划分后会得到(224/16)×(224/16)=196个子图。接着通过线性映射将每个子图映射到一维向量中。
线性映射是通过直接使用一个卷积层来实现,卷积核大小为16×16,步长为16,个数为768,这个卷积操作对输入数据产生张量的形状变化为[224,224,3]→[14,14,768],然后把H以及W两个维度展平即可,张量的形状变化为[14,14,768]→[196,768],此时正好变成了一个二维矩阵,正是Transformer期望的格式。其中196表征的是子图的数量,将每个形状为[16,16,3]的子图数据通过卷积映射得到一个长度为768的Token。
在输入Transformer Encoder之前注意需要加上[class]token以及位置嵌入。在原论文中,作者使用[class]token而不是全局平均池化做分类的原因主要是参考Transformer,尽可能地保证模型结构与transformer类似,以此来证明Transformer在迁移到图像领域的有效性。具体做法是,在经过Linear Projection of Flattened Patches后得到的Tokens中插入一个专门用于分类的可训练的参数([class]token),数据格式是一个向量,具体来说,就是一个长度为768的向量,与之前从图片中生成的Tokens拼接在一起,维度变化为concat([1,768],[196,768]→[197,768])。由于Transformer模块中的自注意力机制可以关注到全部的Token信息,因此我们有理由相信[class]token和全局平均池化一样都可以融合Transformer学习到的全部信息用于后续的分类计算。
位置嵌入采用的是一个可训练的一维位置编码(1D Pos.Emb.),是直接叠加在Tokens上的,所以张量的形状要一样。以ViT-B/16为例,刚刚拼接[class]token后张量的形状是[197,768],那么这里的位置嵌入的张量的形状也是[197,768]。自注意力是让所有的元素两两之间去做交互,是没有顺序的。但是图片是一个整体,子图是有自己的顺序的,在空间位置上是相关的,所以要给Patch嵌入加上了位置嵌入这样一组位置参数,让模型自己去学习子图之间的空间位置相关性。
在卷积神经网络算法中,设计模型时给予模型的先验知识(Inductive Bias)是贯穿整个模型的,卷积的先验知识是符合图像性质的,即局部相关性(Locality)和平移不变性(Transitionally Equivalent)。对于 ViT模型,其关键组成部分之一自注意力层,实施的是全局性的操作。在这个过程中,原始图像的二维结构信息并未显著地发挥作用,只有在初始阶段将图像切分为多个Patch时,该信息被利用。值得强调的是,位置编码在初始阶段是通过随机初始化实现的,此过程并未携带关于Patch在二维空间中位置的任何信息。Patch间的空间关系必须通过模型的学习过程从头开始建立。 因此,ViT模型没有使用太多的归纳偏置,导致在中小型数据集上训练结果并不如CNN。但如果有大数据的支持,ViT可以得到比CNN更高的精度,这在一定程度上反映了模型从大数据中学习到的知识要比人们给予模型的先验知识更合理。
最后,作者对于不同的位置编码方式做了一系列对比实验,结果见表1。在源码中默认使用的是一维位置编码,对比不使用位置编码准确率提升了百分之三,和二维位置编码比起来差距不大。作者的解释是,ViT是在Patch水平上操作,而不是像素水平上。具体来说,在像素水平上,空间维度是224×224,在Patch水平上,空间维度是(224/16)×(224/16),比Patch维度上小的多。在这个分辨率下学习表示空间位置,不论使用哪种策略,都很容易,所以结果差不多。
| 位置编码种类 | 模型精度 |
| 不添加位置编码 | 0.61382 |
| 1D位置编码 | 0.64206 |
| 2D位置编码 | 0.64001 |
| 相对位置编码 | 0.64032 |
3.ViT的Transformer编码器
Transformer编码器其实就是重复堆叠Encoder Block L次,Encoder Block的结构图如图3(a)所示,其主要由以下几部分组成:
(1)层归一化:这种归一化的方法主要是针对自然语言处理领域提出的,这里是对每个Token进行归一化处理,作用类似于批量归一化。
(2)多头注意力:该结构与Transformer模型中的一样,详见https://www.aideeplearning.cn/transformer%e7%ae%97%e6%b3%95/。
(3)Dropout/DropPath:在原论文的代码中是直接使用的Dropout层,但实现的代码中使用的是DropPath(Stochastic Depth),后者会带来更高的模型精度。
(4)MLP 模块:就是“全连接+GELU激活函数+Dropout”组成也非常简单,需要注意的是,第一个全连接层会将输入节点个数增加到4倍,即[197,768]→[197,3072];而第二个全连接层会将节点个数还原回原始值,即[197,3072]→[197,768],结构图如图3(b)所示。
![图片[3]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240212222109386.png)
4.MLP Head模块
通过Transformer编码器后输出的张量的形状和输入的张量的形状是一致的,输入的是[197,768],输出的还是[197,768]。因为只是需要分类的信息,所以提取出[class]token生成的对应结果就行,即[197,768]中抽取出[class]token对应的[1,768]。因为自注意力计算全局信息的特征,这个[class]token其中已经融合了其他Token的信息。接着通过MLP Head得到最终的分类结果。
![图片[4]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205192544758.png)
值得注意的是,关于[class]token和GAP在原论文中作者也是通过一些消融实验来比较效果的,结果证明,GAP和[class]token这两种方式能达到的分类准确率相似。因此,为了尽可能模仿Transformer,选用了[class]token的计算方式,具体实验结果如图5所示。其中,选择GAP的计算方式时要采用较小的学习率,否则会影响最终精度。值得总结的一点是:在深度学习中,有时候操作效果不佳,不一定是操作本身存在问题,也有可能是训练策略的问题,即“炼丹技巧”。
![图片[5]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205192734664.png)
5.模型缩放
从表2中可以看到,论文给出了三个不同大小的模型(Base/ Large/ Huge)参数,其中Layers表示Transformer编码器中重复堆叠Encoder Block的次数,Hidden Size表示对应通过嵌入层后每个Token的向量的长度(Dim),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads表示Transformer中多头注意力的注意力头数。
| Model | Patch Size | Layers | Hidden Size | MLP size | Heads | Params |
| ViT-Base | 16×16 | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 16×16 | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 14×14 | 32 | 1280 | 5120 | 16 | 632M |
6.混合ViT模型
混合模型(Hybrid-ViT),就是将传统CNN特征提取和Transformer进行结合。该模型在浅层使用卷积结构,在深层使用Transformer结构。混合模型如图6所示,其中以ResNet50作为特征提取器的混合模型,不过这里的ResNet50与原论文中的ResNet50略有不同。
通过ResNet50 Backbone进行特征提取后,得到的特征矩阵张量的形状是[14,14,1024],然后输入Patch Embedding层,注意Patch Embedding中卷积层的卷积核尺寸和步长都变成了1,只是用来调整通道数,最终的张量形状也会变成[196,768]。模型的后半部分和前面ViT的结构完全相同。
![图片[6]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205193719213.png)
实验结果如图7所示,横轴表示模型的计算复杂度,即模型大小;竖轴是分类准确率。在五个数据集上的综合表现如图7(a)所示,在ImageNet数据集上的表现如图7(b)所示。结果表明,当模型较小时,Hybrid-ViT表现最好,因为Hybrid-ViT综合了两个算法的优点。但是,当模型较大时,ViT模型的效果最好,这在一定程度上说明了ViT模型自己从数据集中学习到的知识比人们根据先验赋予CNN模型的知识更有意义。
![图片[7]-ViT:视觉Transformer-VenusAI](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240205194313200-1024x428.png)
7.ViT小结
ViT的出发点是想证明,从自然语言处理领域迁移过来的模型Transformer同样可以很好地处理图像数据,尤其是在大数据的支持下。这一点首次动摇了CNN模型在计算机视觉领域的统治地位。因此,很多学者都想要深入探究是什么让Transformer模型效果如此出色?
由于Transformer的论文中力推自注意力机制,之后的很多年,人们都先入为主地认为自注意力在Transformer中起到了重要作用,但是最近的一些文章证明了它并非Transformer中必不可少的操作。MLP-Mixer: An all-MLP Architecture for Vision将ViT中Transformer编码器中的多头注意力操作换成了MLP,模型依然可以获得不错的性能,这个工作证明了自注意力并不是Transformer中成功的唯一关键因素。值得注意的是,当把多头自注意力机制操作换成了MLP,整个ViT模型其实变成了一个MLP模型,回到了深度学习的起点算法——神经网络算法。最终形成了CNN、Transformer、MLP三足鼎立的态势。
另外,有些激进的学者直接将Transformer中的自注意力替换成了没有可学习参数的池化层,例如论文Metaformer is actually what you need for vision。令人惊讶的是,这种做法的模型仍然能够获得不错的性能表现。因此,这些学者认为,Transformer成功的关键在于整体的模型框架设计,他们将这个框架称为MetaFormer。虽然学术界对于Transformer为何如此有效尚无统一答案:有人说,Self-attention is all you need;有人说, MLP is all you need;有人说,Patch is all you need;也有人说,MetaFormer is all you need。依笔者所见,Transformer之所以能取得优异的性能表现,离不开大量的训练数据和计算资源的支持。因此,从某种意义上来说,答案就是Money is all you need!
在CV中,深度学习算法最初从MLP发展到CNN,又从CNN发展到Transformer,如今看上去又回到了MLP,但是这种模型,如MLP-Mixer,已经有了改进,成为了一个全新的算法。历史上,技术的发展总是螺旋上升的。笔者十分期待,经过Transformer和MLP的冲击后,CNN是否能厚积薄发,重夺在计算机视觉领域的统计地位。















暂无评论内容